Predictive Analytics for Identifying High-Risk Patients
Predictive Modeling Techniques
Predictive analytics leverages various statistical and machine learning techniques to forecast future outcomes. These techniques range from simple regression models to complex algorithms like neural networks and support vector machines. Choosing the appropriate model depends heavily on the nature of the data and the specific prediction goal. Understanding the strengths and limitations of each technique is crucial for building accurate and reliable predictive models.
Different types of predictive models, each with its own strengths and weaknesses, are employed depending on the specific context. For example, linear regression is suitable for predicting continuous variables, while logistic regression is used for categorical outcomes. Time series analysis is employed when dealing with data collected over time, allowing for the identification of patterns and trends to forecast future values.
Data Preparation and Feature Engineering
A crucial aspect of predictive analytics is data preparation. This involves cleaning, transforming, and preparing the data for analysis. This often includes handling missing values, outlier detection, and data normalization, all of which are essential for ensuring the accuracy and reliability of the predictive model. Poorly prepared data can lead to inaccurate predictions and unreliable insights.
Feature engineering is another critical aspect of data preparation. This involves creating new features from existing ones to improve the model's predictive power. By extracting relevant information from the raw data, you can enhance the model's ability to identify patterns and relationships, leading to more accurate predictions. Feature engineering often requires domain expertise to understand the most important factors affecting the outcome.
Model Evaluation and Validation
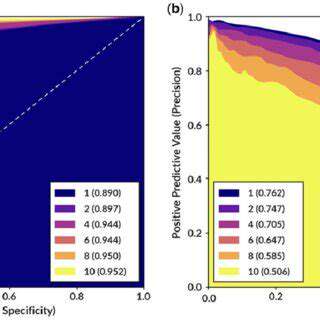
Validating the predictive model is essential to determine its effectiveness and reliability. This process involves evaluating the model's performance on a separate dataset, known as the testing set, that was not used in training the model. Common evaluation metrics include accuracy, precision, recall, F1-score, and root mean squared error, depending on the type of prediction task. Choosing the right metrics is crucial for assessing the model's performance against the desired outcome.
Rigorous validation steps help ensure that the model generalizes well to new, unseen data. Techniques like cross-validation are employed to assess the model's robustness and stability across different subsets of the data. This process helps in identifying potential issues and biases in the model, leading to iterative improvements and enhancements.
Deployment and Monitoring
Once a predictive model is deemed reliable, it needs to be deployed into a production environment to generate actionable insights. This often involves integrating the model with existing business systems, such as customer relationship management (CRM) systems or marketing automation platforms. The successful deployment of a predictive model requires careful consideration of its integration with existing systems and workflows. This integration process ensures that the predictions are utilized effectively within the organization. Furthermore, ongoing monitoring of the model's performance is essential to detect any changes in the underlying data distribution that could impact the accuracy of future predictions.
Regularly monitoring model performance is critical to maintain accuracy. As data evolves, the model may need retraining or adjustments to remain effective. This ensures that the insights generated are reliable and valuable over time. Addressing any performance degradation early allows for timely adjustments and maintains the model's predictive power.