Data Collection: The First Brick
Gathering data serves as the bedrock for any machine learning initiative. This preliminary stage requires pinpointing the precise data needed to tackle the problem at hand. Grasping the context and potential biases within data sources is absolutely essential. A well-crafted data collection strategy guarantees the data mirrors real-world scenarios accurately, laying a sturdy foundation for later analysis and model development. This typically demands careful planning, weighing factors like data quality, accessibility, and ethical considerations surrounding data collection. Establishing clear parameters for the process - including scope, frequency, and collection methods - proves vital. Such systematic approaches minimize errors and ensure data consistency.
Methods for gathering data vary from structured surveys and databases to unstructured social media content and sensor outputs. Selecting appropriate methods hinges on the problem's nature and available resources. Maintaining data quality through validation and verification steps remains paramount. This means spotting and resolving potential inconsistencies, inaccuracies, and missing values in the collected information. Rigorous data cleaning and preprocessing often become necessary to guarantee the data's accuracy and reliability for machine learning applications.
Data Preparation: Shaping the Brick
Raw data frequently requires substantial transformation before becoming useful for machine learning models. This phase, commonly called data preparation, involves cleaning, transforming, and structuring data to make it analysis-ready. The meticulous process includes addressing missing values, correcting inconsistencies, and converting data into machine-readable formats. Understanding data characteristics and relationships proves crucial for selecting proper preprocessing techniques. These might involve normalization, standardization, or feature engineering to extract meaningful patterns from raw data and create valuable model inputs.
Data preparation significantly influences machine learning model performance, making it a pivotal step in the process. Poorly prepared data can yield inaccurate predictions, biased outcomes, and ultimately, faulty decisions. The prepared data's quality directly affects model reliability and effectiveness. Choosing suitable tools and techniques ensures efficient data preparation, making the data appropriate for intended machine learning tasks. Since data preparation often requires multiple iterations of cleaning, transformation, and validation, it's typically an ongoing process to achieve optimal results.
Data Exploration and Analysis: Understanding the Brick
Before constructing complex models, comprehending underlying data patterns and relationships is essential. Data exploration employs various statistical methods and visualization tools to identify trends, anomalies, and potential biases. This stage aids in understanding data structure and characteristics, guiding appropriate algorithm selection. Exploring data reveals variable relationships and potential confounding factors - insights critical for developing effective machine learning strategies and accurate models.
Visualization proves indispensable here, helping identify trends, outliers, and possible correlations. Statistical summaries like descriptive statistics and histograms offer additional data distribution insights. Careful analysis can uncover issues like missing values or outliers that might impact subsequent machine learning results. This exploratory phase not only refines the machine learning process but also identifies potential data gaps requiring additional collection efforts.
Thorough data exploration enables informed decisions about machine learning techniques, feature selection, and overall model design. It empowers data scientists to make reasoned choices, leading to more precise and dependable models. By grasping data nuances, we can build models that reflect real-world complexities more accurately.
Predictive Power for Future-Forward Decisions
Harnessing the Potential of Predictive Analytics
Predictive analytics, a potent data science subset, is revolutionizing industries by helping organizations anticipate future trends and outcomes. Analyzing historical data with sophisticated algorithms allows businesses to spot patterns and anomalies, leading to better decision-making and strategic planning. This predictive capability enables companies to proactively tackle challenges and seize emerging opportunities. Such forward-thinking proves crucial in today's volatile business environment, where adaptability determines survival and success. Moreover, predictive analytics helps businesses optimize resource allocation and minimize potential risks effectively.
Predicting market fluctuations, customer behavior, and operational efficiency can significantly boost company performance. This proactive stance reduces unexpected events' impact, letting businesses adjust strategies and maintain competitive advantages. Understanding various scenarios' potential implications helps organizations develop robust contingency plans and mitigate risks, safeguarding their future trajectory. Data-driven insights from predictive analytics substantially contribute to informed decision-making, enabling efficient resource allocation and return maximization.
Enhancing Decision-Making Through Data-Driven Insights
Data-driven insights prove essential for sound business decisions. Predictive analytics offers a framework for understanding potential future outcomes, helping organizations navigate uncertainty and make strategic choices aligned with long-term objectives. This approach fosters proactive, anticipatory problem-solving, keeping businesses ahead of trends and ready to capitalize on new opportunities.
By leveraging historical data, predictive models can uncover significant trends and patterns that might otherwise remain hidden. This deeper comprehension of market dynamics, customer preferences, and operational processes enables more informed, strategic decisions. Forecasting future performance helps businesses allocate resources optimally and refine strategies for desired outcomes. This data-focused approach promotes accountability and transparency, improving cross-departmental collaboration and communication.
Predictive analytics extends beyond identifying potential challenges; it provides actionable insights for addressing them. Understanding risk-contributing factors lets organizations implement preventative measures and build resilience against unforeseen events. This proactive risk management approach protects financial interests while safeguarding reputation and long-term stability. Such forward-thinking fosters continuous improvement, helping organizations adapt to changing market conditions and maintain competitiveness.
Beyond the Algorithm: Data Preparation and Model Evaluation
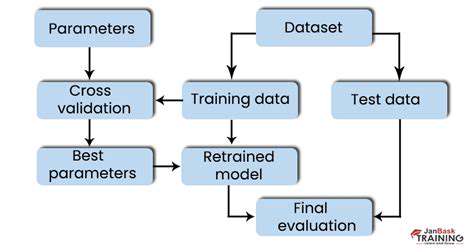
Data Cleaning: The Unsung Hero
Data cleaning, though frequently underestimated, remains absolutely critical for machine learning success. This process identifies and corrects or removes inaccurate, incomplete, or irrelevant data points. Such errors can dramatically skew results, producing flawed models and poor decisions. Prioritizing data quality ensures models train on reliable information, enabling more accurate predictions and actionable insights.
Cleaning techniques range from simple data imputation to advanced methods like outlier detection and transformation. Understanding data nuances and applying appropriate cleaning strategies is fundamental for building robust, reliable models. This step often requires multiple iterations to ensure data purity, establishing a strong foundation for subsequent preparation stages.
Feature Engineering: Crafting Meaningful Inputs
Feature engineering transforms raw data into more meaningful model inputs. This involves creating new features from existing ones or selecting the most relevant from large datasets. Well-engineered features help models capture complex data relationships and patterns, improving predictive performance.
As a crucial data preparation aspect, feature engineering directly affects a model's learning and generalization capabilities. Careful consideration must go into feature types and representation methods. A well-designed feature set can dramatically enhance a model's ability to understand data and make accurate predictions.
Data Transformation: Shaping the Data for Model Success
Data transformation - a fundamental preparation step - converts data into machine-learning-friendly formats. This includes scaling numerical features, encoding categorical variables, and handling missing values. These transformations ensure all features contribute equally to model training, preventing larger-valued features from dominating outcomes.
Proper data transformation is indispensable for effective model operation. Different algorithms require specific data formats, making transformation critical for preparing data across various machine learning tasks. Correct preparation improves a model's ability to identify meaningful patterns and relationships, yielding superior results.
Handling Imbalanced Datasets: Addressing the Bias
Imbalanced datasets, where one class vastly outnumbers others, present common machine learning challenges. Such imbalances can bias models toward majority classes, impairing minority class classification accuracy. Addressing this bias demands careful consideration and specialized techniques to ensure models learn from all classes effectively.
Strategies for handling imbalanced datasets include oversampling minority classes, undersampling majority classes, or using algorithms specifically designed for class imbalance. Understanding imbalance implications and implementing appropriate solutions is essential for developing robust, fair machine learning models that treat all data points equitably.
Data Validation and Testing: Ensuring Model Reliability
Data validation and testing are essential for verifying prepared data quality and reliability. These steps check for inconsistencies, missing values, and outliers. Thorough validation identifies potential issues early, preventing them from affecting model performance.
Comprehensive data validation is crucial for spotting problems and ensuring model accuracy. Rigorous testing across various scenarios and data points confirms model reliability and real-world applicability. This builds essential trust in the model and its outputs.