The Growing Role of Artificial Intelligence in Lung Cancer Detection
Early Detection and Diagnosis
Modern medicine is witnessing a paradigm shift with the integration of artificial intelligence into diagnostic processes, particularly in the realm of lung cancer identification. Advanced computational systems now process medical imagery, including CT scans and radiographic images, with unprecedented efficiency. These systems excel at spotting minute irregularities that might escape human observation, potentially flagging cancerous growths before clinical symptoms manifest. Such early intervention opportunities dramatically improve therapeutic outcomes and patient survival probabilities.
The analytical capacity of machine learning models enables them to sift through enormous repositories of medical imaging data. This allows for the creation of refined algorithms capable of differentiating between harmless tissue variations and potentially dangerous malignancies. Such precision in diagnosis helps avoid unnecessary procedures stemming from false alarms, a common drawback of conventional screening protocols. The net result is a more streamlined diagnostic pathway with optimized treatment timing.
Improved Accuracy and Efficiency
Computational diagnostics offer significant improvements in both precision and operational speed. Through exposure to vast collections of annotated medical images, these systems develop an exceptional ability to recognize patterns in pulmonary tissue. This training process yields detection capabilities that frequently surpass human radiologists in both speed and accuracy, particularly in identifying early-stage abnormalities. The reduction in diagnostic errors directly correlates with improved patient prognoses.
Automation plays a pivotal role in modern diagnostic workflows. Intelligent systems can handle numerous aspects of the evaluation process independently, from initial image assessment to preliminary report generation. This automation dramatically shortens the interval between imaging and diagnosis, ensuring patients receive critical care interventions more rapidly. In oncology, where time is often of the essence, such efficiency gains can be life-saving.
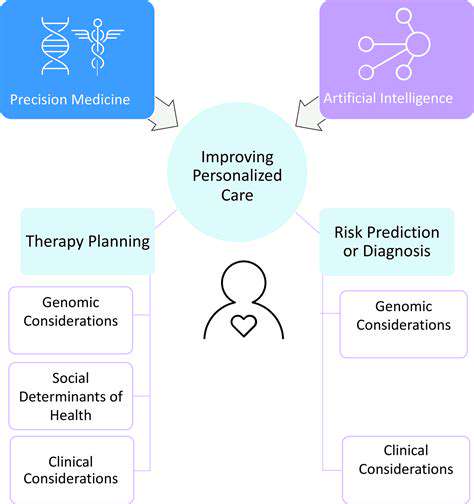
Personalized Treatment Strategies
The application of machine learning extends beyond detection into therapeutic planning. By synthesizing patient-specific data - including genomic markers, tumor morphology, and historical treatment responses - these systems can recommend customized therapeutic regimens. This tailored approach frequently results in superior clinical outcomes compared to standardized treatment protocols.
Enhanced Radiologist Support
Rather than replacing medical professionals, intelligent systems function as sophisticated diagnostic aids. These tools can pre-process medical images, flagging areas requiring closer inspection. Such collaborative workflows allow radiologists to concentrate their expertise where it's most needed, simultaneously improving diagnostic precision and reducing interpretation time. The synergy between human expertise and machine efficiency proves particularly valuable in the nuanced evaluation of pulmonary nodules.
Minimizing Bias and Improving Accessibility
When developed with comprehensive, diverse training datasets, computational diagnostic systems can help overcome inherent biases in traditional diagnostic approaches. By processing information without human perceptual limitations or unconscious prejudices, these models offer more objective evaluations. This characteristic makes them particularly valuable for ensuring equitable healthcare access across diverse demographic groups, potentially reducing disparities in cancer diagnosis and treatment.
Future Applications and Research
The frontier of computational diagnostics continues to expand, with current investigations focusing on algorithm refinement, dataset expansion, and integration with complementary diagnostic technologies. Future iterations will likely incorporate more sophisticated analytical techniques and predictive modeling capabilities. Concurrent research explores the potential for identifying novel biomarkers through machine learning approaches, which could revolutionize early detection methodologies and treatment response prediction.
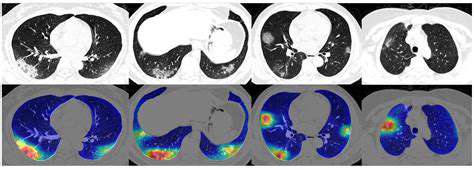
Improving Accuracy and Reducing False Positives

Improving Data Collection Techniques
The foundation of any reliable analysis lies in meticulous data acquisition. Establishing rigorous data collection protocols is essential for minimizing inaccuracies and ensuring result validity. This requires precise definition of data requirements, implementation of standardized recording procedures, and deployment of appropriate technological solutions. Comprehensive documentation of the collection methodology enables researchers to monitor potential biases and verify data integrity. Incorporating multiple independent data sources provides additional validation layers, helping to identify and account for anomalies.
Participant selection demands careful consideration. Utilizing representative cohorts, avoiding selection biases, and obtaining proper consent all contribute to the reliability of gathered information. The sampling strategy fundamentally influences the credibility of subsequent findings, making its careful design paramount.
Enhancing Data Analysis Methods
Sophisticated analytical approaches complement thorough data collection efforts. Appropriate statistical methodologies must be employed to uncover meaningful patterns and correlations within datasets. Initial exploratory analysis, including various visualization techniques and descriptive statistics, helps identify potential data quality issues and validates the suitability of chosen analytical methods.
Modern computational techniques, particularly machine learning algorithms, offer powerful tools for discerning complex relationships within data. These methods frequently reveal insights that conventional analytical approaches might overlook, leading to more nuanced interpretations and predictions.
Validating Results and Reducing Errors
Comprehensive validation procedures are critical for ensuring result accuracy. This involves systematic examination of findings for potential flaws, biases, or inconsistencies. Cross-referencing outcomes with established scientific knowledge helps confirm validity and identify potential contradictions. The process should also address any systematic errors that may have affected either the data or analysis.
Replicating analyses using alternative datasets or methodologies strengthens confidence in the results. Such multi-faceted approaches provide more robust and reliable conclusions than single-method analyses.
Implementing Quality Control Measures
Consistent quality assurance protocols throughout the research process are vital for minimizing errors. This requires implementing verification checkpoints at every stage, from initial data gathering to final interpretation. Standardized procedures for data validation significantly reduce the likelihood of errors persisting through the analysis pipeline.
Proper training of all personnel involved in data handling ensures methodological consistency. Regular audits and procedural reviews maintain quality standards, particularly important in extended longitudinal studies where procedural drift can occur.